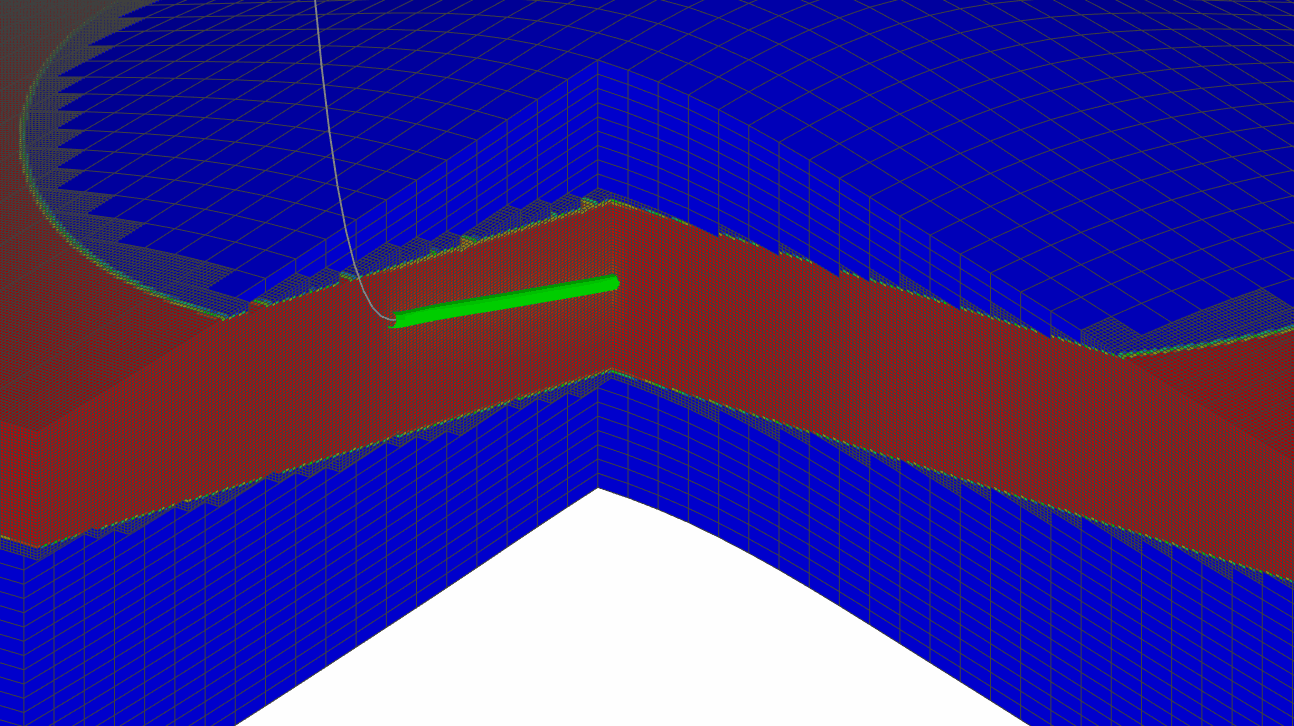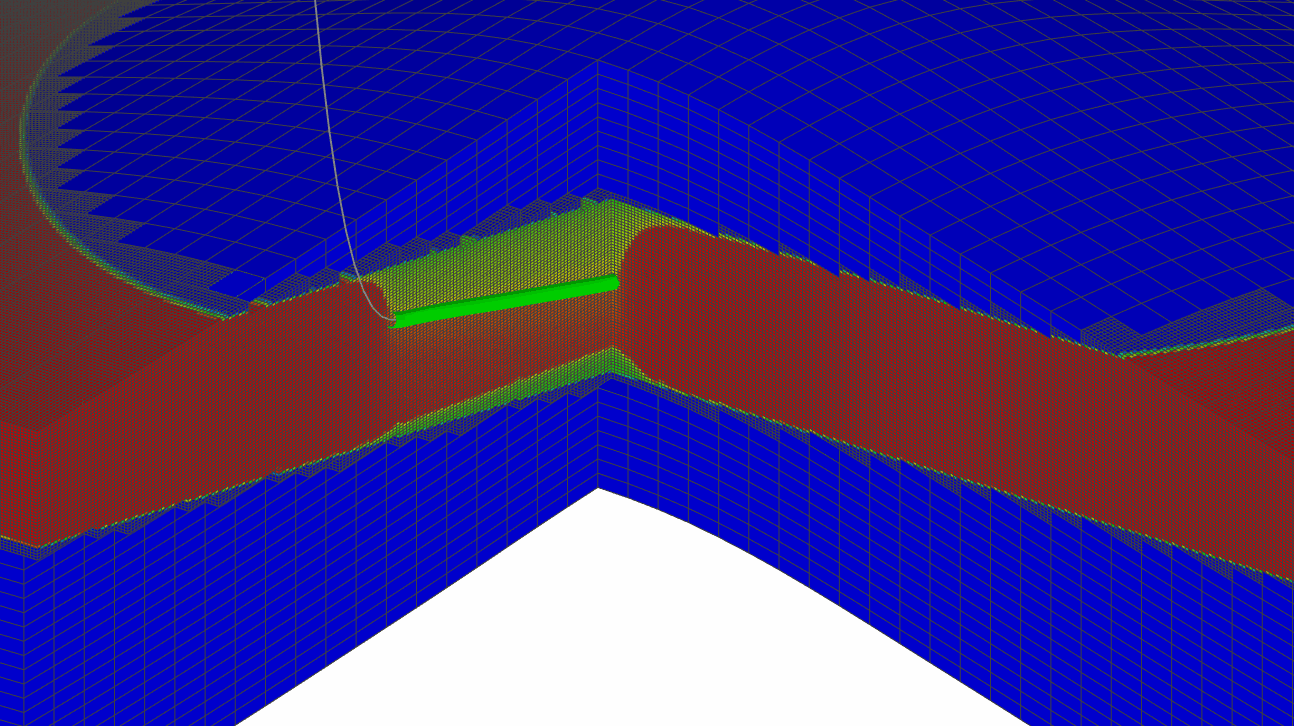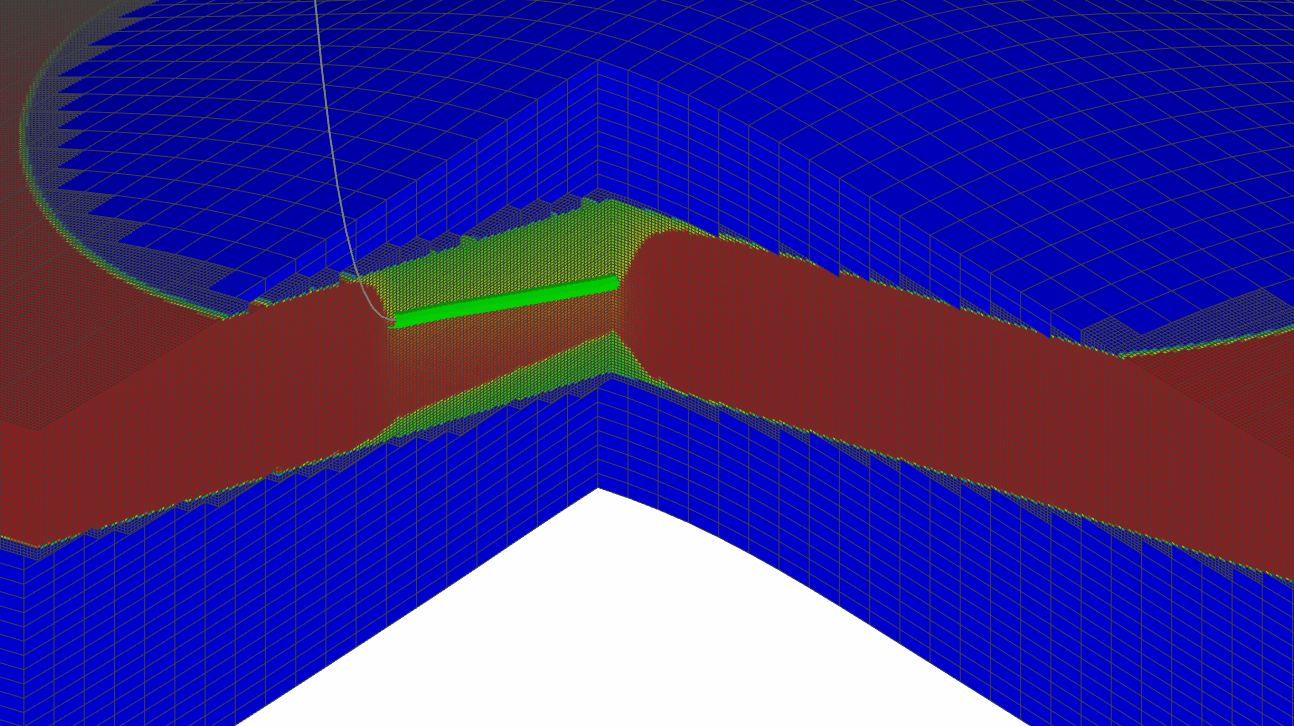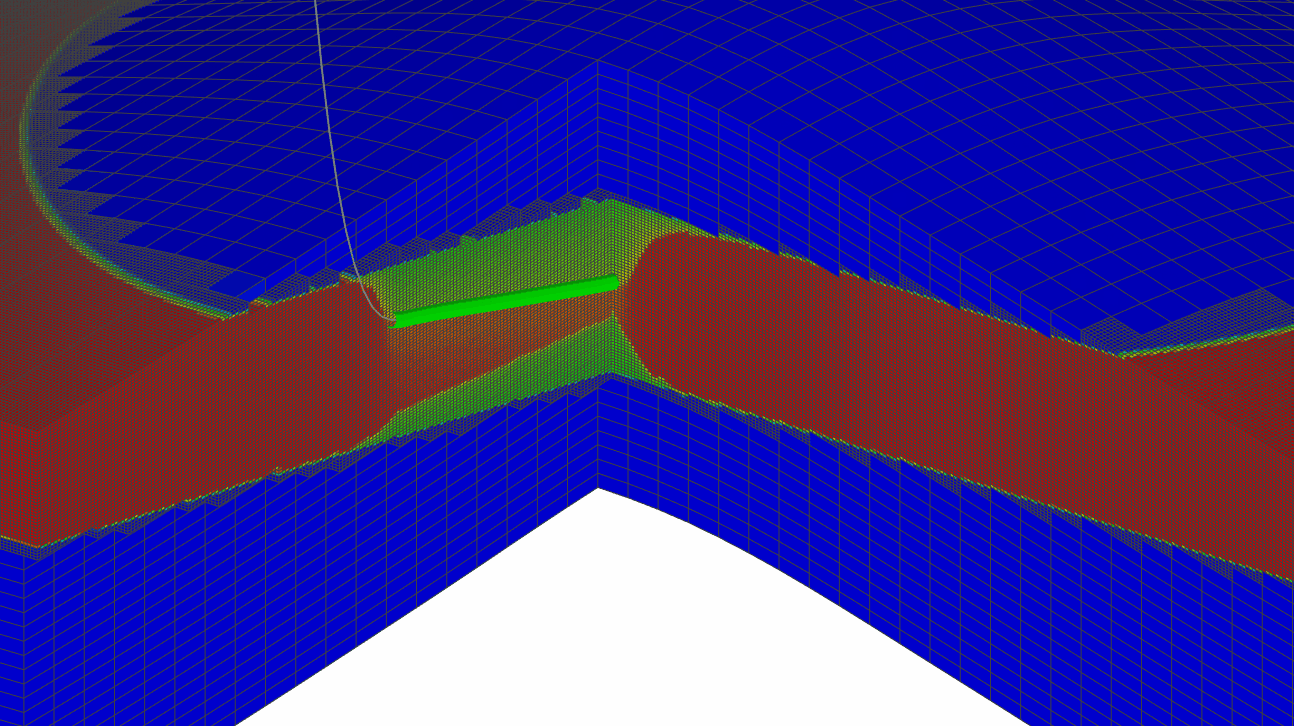
Точное моделирование процессов, протекающих в районе скважины
В случаях, когда в пласте наблюдаются такие сложные процессы, как:
- конусообразование
- выпадение конденсата в призабойной зоне
- изменение фильтрационных свойств ПЗП
- проведение операций гидроразрыва в низкопроницаемых коллекторах
- закачка пара / SAGD
- моделирование fishbones с параметризацией траектории в LGR
- настройка модели на результаты ГДИС
и т.п., то точно смоделировать данные процессы на грубой сетке практически невозможно. Возникает необходимость производить уточнение модели путем создания локальных измельчений (LGR) или проведения downscaling всей сетки. Однако, создание дополнительных измельченных ячеек неизбежно приведет к увеличению нагрузки на пропускную способность памяти и CPU, т.к. возрастает количество активных блоков, что приведет к увеличению нагрузки на симуляционные процессы: меняется динамика флюида, физические процессы модели, фазовое состояние, состав смеси и подвижность фаз за счет более точного описания притока к стволу скважины.
Для того чтобы уточнение модели не приводило к существенному замедлению расчета, нужно эффективно использовать вычислительные мощности современных рабочих станций и кластеров. В основе расчетного ядра тНавигатор лежат высокоэффективная многоуровневая «гибридная» схема распараллеливания, использующая как потоки, так и MPI, неравномерный доступ к памяти (NUMA), многоуровневая балансировка загруженности (учет активных блоков, распределения скважин…), большой кэш CPU. Таким образом, насыщенность масштабируемости не наступает при увеличении числа ядер, а ускорение ограничено только пропускной способностью памяти.
Однако, самым главным выбором при использовании уточненной модели притока за счет увеличения количества ячеек LGR в скважину будет являться расчет на графических ядрах (GPU). GPU является основным выбором высокопроизводительных вычислений, т.к. малая мощность CUDA ядер сочетается с их большим количеством, что позволяет распараллеливать модель не только между всеми ядрами процессора (CPU), а также полностью заполнить ядра GPU новыми измельченными ячейками. Данные технологии позволяют быстро и эффективно считать даже самые сложные модели и более не нужно останавливаться на компромиссе между временем расчета и количеством активных блоков. Для достижения максимальной производительности таких моделей рекомендуется включать в настройках одновременное использование 2хGPU (минимальное количество ячеек на один GPU ~700 000).